亚博体育从而变成圆善的学问树-亚博提款出款是秒到账
仅使用 20K 合成数据亚博体育,就能让 Qwen 模子才调飙升——
模子主不雅对话才调显耀提高,还能竣事模子自我迭代。
合成数据大法好!

最近,来自上海 AI Lab 的商量团队针对合成数据本领伸开商量,建议了 SFT 数据合成引擎 Condor,通过天下学问树(World Knowledge Tree)和自我反想(Self-Reflection)机制,探索合成海量高质料 SFT 数据的有筹划。
适度,他们还不测发现,在增大合成数据量的情况下,模子性能执续提高。
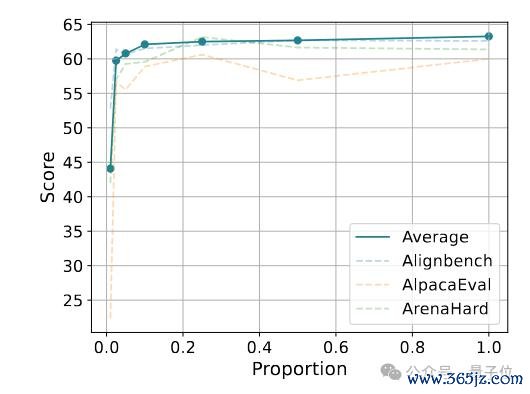
从 5K 数据量入手,模子主不雅对话性能跟着数据量加多而提高,但数据量达到 20K 后,性能增长变缓——
LLM 数据合成新范式:基于天下学问树打造高质料对话数据
跟着大模子才调的快速发展,模子考试对高质料 SFT 数据的需求日益遑急。数据合成本领四肢一种新颖高效的数据生成计策,缓缓成为商量热门,并在模子迭代历程中演出着要害变装。
上海 AI Lab 商量团队的 Condor 数据合成主要包含两个阶段:Condor Void 和 Condor Refine。
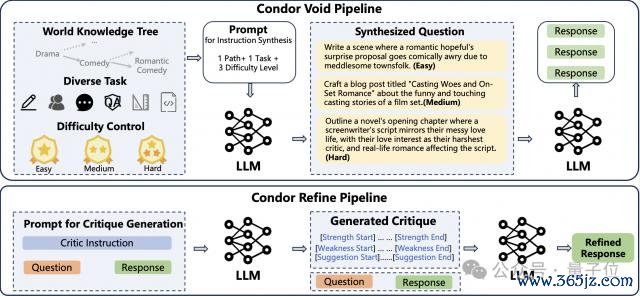
扫数这个词历程中,商量团队仅使用一个 LLM 四肢运行模子,同期承担问题合成、复兴合成、复兴评价和复兴转换的多重变装。
使用天下学问树进行种种化提醒合成。
具体来说,Condor 当先哄骗模子生成一系列天下学问树,给定模子一些要害词,让其自己递归生成更多的子要害词,从而变成圆善的学问树。每个节点四肢一个 Tag,用于后续数据生成。
举例,给定"东说念主工智能"这个要害词,生成一条由粗到细的学问链路:
东说念主工智能——深度学习——筹备机视觉——自动驾驶——单目办法检测
Condor 以这条学问链路四肢配景学问,条款模子生成相干问题。为进一步提高合成提醒的种种性,商量团队引入了任务种种性和问题难度种种性的增广条款。
针对不同类型的主不雅任务(如常常聊天、变装演出、创意创作等),商量东说念主员经心遐想了不同的问题模板来招引模子生成对应任务下的问题。在生成问题时,Condor 条款模子在一次生成中同期生成三种不同难度的问题。
自我反想提高复兴质料
关于每一条学问链路,基于 Condor 不错采集到不同任务类型、不同难度的多个问题。商量东说念主员将这些问题输入模子,生成启动复兴,得到第一版的 SFT 合成数据。
Condor Refine Pipeline 引入自我反想计策,使用模子对第一版复兴进行评价并生成修改想法,招引模子进一步转换复兴,从而得到最终的高质料 SFT 数据。
使用合成数据提高模子通用对话才调
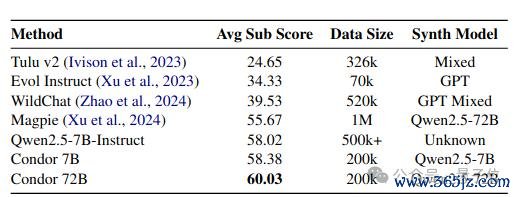
商量东说念主员使用开源模子 Qwen2.5-72B-Instruct 进行数据合成,得到 Condor Void 和 Condor Refine 两个版块的合成数据,并基于 Qwen2.5-7B 进行 SFT 考试,测试其主不雅对话才融合客不雅抽象才调。
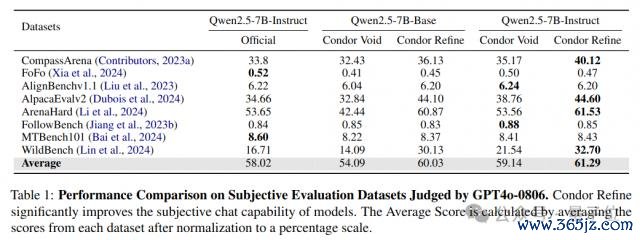
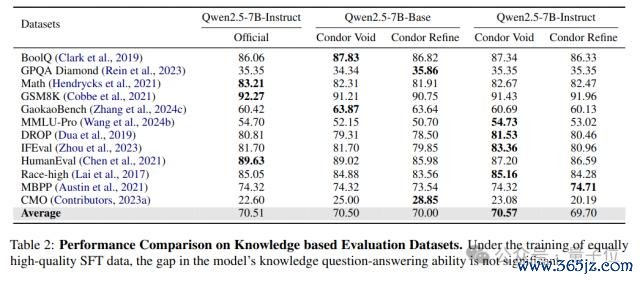
从践诺适度不错看出,使用 Condor 合成数据考试的模子在主不雅对话才调上与 Qwen2.5-7B-Instruct 具有竞争力。
同期,基于 Condor 合成数据考试的模子在主流客不雅评测基准上保执了性能。Condor 比拟其他基线枢纽具有显耀的性能上风。
数据限度影响与模子自我迭代
商量团队进一步探索在增大合成数据量的情况下,模子性能能否执续提高。
从 5K 数据量入手,渐渐加多到 200K,不雅察不同数据量下考试出的模子性能。
适度露出,模子主不雅对话性能跟着数据量加多而提高,但数据量达到 20K 后,性能增长变缓。
哄骗合成数据能否竣事模子的自我迭代呢?
商量团队哄骗 Qwen2.5-7B-Instruct 和 Qwen2.5-72B-Instruct 模子经过 Condor Pipeline 生成两版数据,并永诀考试 7B 和 72B 的 Base 模子,不雅察自我迭代服从。
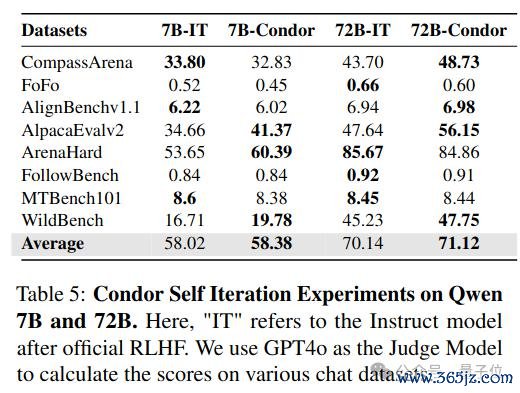
从适度不错看出,经过 Condor 合成数据考试,模子在 7B 和 72B 上均竣事了自我迭代,比拟基线性能进一步提高。
合成数据为什么有用?
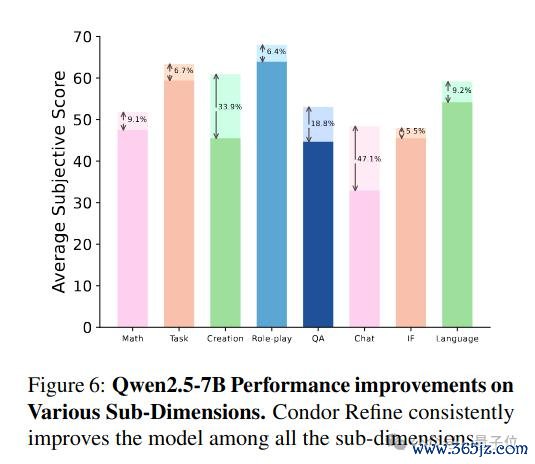
Condor 的合成数据怎样对模子产生增益作用?商量团队进行了一系列分析。商量东说念主员将主不雅评测集按各个才调维度拆解,统计在各个维度上的增益,发当今扫数维度上齐产生了增益,在 Creation、QA 和 Chat 上的增益尤为昭着。
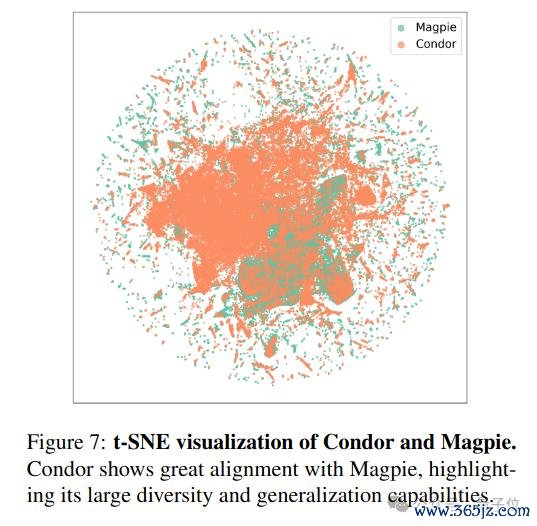
进一步的,商量东说念主员对 Condor Pipeline 合成的问题提醒进行分析。使用 T-SNE 投影与 Magpie 枢纽合成的问题进行对比,发现 Condor 合成的数据和 Magpie 均能竣事鄙俚的学问粉饰。
再来望望模子在对话复兴中的证据,通过和原始模子进行对比咱们不错发现,Condor 合成的数据考试后的模子即使和官方模子比拟,在复兴格调(如幽默,创意)的主不雅感受上也要更胜一筹,能愈加拟东说念主化并推敲到回答细节的改善。

合成数据是大模子迭代的首要有筹划,仍有好多值得探索的商量问题,如高质料推理数据和多轮对话数据的有用合成计策、着实数据和合成数据的相助配比机制、以及怎样冲突合成数据的 Scaling Law 等。咫尺,Condor 的合成数据和考试后的模子均已开源,迎接社区用户体验和探索。
Github: https://github.com/InternLM/Condor
数据集:https://hf.co/datasets/internlm/Condor-SFT-20K
论文:https://arxiv.org/abs/2501.12273
— 完 —
投稿请发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉咱们:
你是谁,从哪来,投稿骨子
附上论文 / 形态主页结合,以及斟酌形势哦
咱们会(尽量)实时复兴你

一键崇敬 � � 点亮星标
科技前沿进展逐日见
一键三连「点赞」「转发」「防范心」
迎接在指摘区留住你的想法!亚博体育
热门栏目 自选股 数据中心 行情中心 资金流向 模拟往复 客户端 中国生物制药(01177)早盘高潮4.28%现金葡萄京娱乐城app平台,现报3.41港元,成交额1.13亿港元。 中国生物制药发布公告,集团与礼新医药科技(上海)有限公司(礼新医药)签署股权投资及政策互助契约。集团以自筹资金入股礼新医药,并就LM-108及异日潜在的多个编削双特异性抗体或抗体偶联药物(ADC)在中国大陆地区已毕政策互助。 海量资讯、精确解读,尽在新浪财经APP 背负裁剪:卢昱君 现金葡萄京娱乐城app平台
查看更多->
11月20日上昼,华嵘控股复牌跌停九游体育娱乐网,控股鼓吹阻隔盘算控股权变更事项,此前曾屡次跨界未果。 海量资讯、精确解读,尽在新浪财经APP
查看更多->
炒股就看金麒麟分析师研报,巨擘,专科,实时,全面云开体育,助您挖掘后劲主题契机! 近日,辽宁证监局线路了一则《对于对中天证券股份有限公司沈阳枫杨路证券商业部接受出具警示函行径的决定〔2024〕21号》的公告,直指中天证券沈阳枫杨路商业部三项违法问题。 公告泄漏,中天证券沈阳枫杨路证券商业部暴雷三方面违法,一是客户回拜责任不到位,二是客户司理从事回拜责任,三是部分汇注直播未报备也未进行合规管控,向客户提供的部分投资提议枯竭合理依据,留痕纪录不竣工。 辽宁证监局示意,依据关连法律规矩,决定对该商业
查看更多->